
How many times in your career have you heard the phrase “Don’t waste your time by reinventing the wheel. Someone else has already done it for you.”
Sometimes it’s true. But how much time I’m going to waste in order to read, understand and finally convert (adapt) my code to the third party library. And of course, will the final result be better (in terms of quality – clear, testable and well performed )? Have you ever been wondered how easy or difficult might be let’s say the implementation of a machine learning algorithm ?
I’ve been working once for a company that was specialized in the domain of data analysis and machine learning and a key member of that company was a well respected scientist with a great academic background. There was the need to implement things like PCA (Principal Component Analysis), KNN, Lasso etc. In order to provide this functionality, the scientist decided that it will be better to utilize the packages provided by the R (in a future post I will show how you can connect to the RServer from withing Java application) for the analysis part while the non-analytics part was a simple n-tier application written in JAVAEE 7. Was it actually faster ( in terms of delivering faster ) ? Let’s try to break the myth by implementing our own KNN classifier with the help of Java 8.
The KNN (K-Nearest Neighbors) is one of those algorithms that it is ridiculously simple although provide pretty good results. The only mathematical tool you need to know is the Euclidean distance between two vectors (or any other distance measure). On the other hand, that simplicity comes at the cost of performance since in order to find the nearest neighbors of the given sample all training data should be considered.
KNN works as follows: Given a positive integer K ( number of neighbors ) and a test observation x, the KNN classifier first identifies the K points in the training data that are closes to x. It then lets the closest neighbors to vote and the most voted class is assigned to the test observation[1].
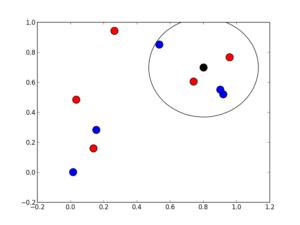
The image above displays the case where the KNN classifier has found the 5-Nearest Neighbors ( training data : blue and red dots ) of the test observation ( black dot ). The neighbors vote and the result is blue=3 and red=2 and so the the test observation belongs to the blue class ( at least with confidence 3/5=60%)
The algorithm is summarized in the steps bellow:
- 1.Compute the K closes neighbors for the given sample x
- 2.Let the neighbors vote for their class
- 3.The majority class is the class that the sample belongs to
The sample and the training data are the objects of your domain model ( or any other model ). But since the KNN uses a distance measure for finding the neighbors, how does it know how the distance is defined between two objects of your domain model ?
The answer is that it doesn’t know. KNN classifier expects from its client ( invoker) to provide a way ( function ) for describing how the distance will be measured ? For such purposes I thouht that a generic Descriptor interface would be quite useful.
Furthermore, any domain model class has the private instance members ( fields ). In the Machine Learning vocabulary these are called features. So it would be nice to add another method on the Descriptor interface for getting the functions that give me the values of these features ( references to accessor methods ).Java 8 introduced many new features and concepts and in my opinion the best of the them was the functional nature. And this is the feature we are going to utilize in order to “describe” the data measurements.
The Descriptor interface
package com.tns.ml.api;
import java.util.Comparator;
import java.util.List;
import java.util.function.BiFunction;
import java.util.function.Function;
import org.apache.commons.math3.ml.distance.ChebyshevDistance;
import org.apache.commons.math3.ml.distance.EuclideanDistance;
import org.apache.commons.math3.ml.distance.ManhattanDistance;
import com.tns.ml.common.Feature;
import com.tns.ml.stats.SummaryStatistics;
/**
* The purpose of this class is to provide functionalities used by the
* algorithms for a specific class
*
* @author sergouniotis
*
* @param <T>
*/
public interface Descriptor<T> {
default SummaryStatistics<T> summaryStatistics() {
return new SummaryStatistics<T>(comparator(), add(), divide());
}
/**
* Return the function for computing the distance between two entities. The
* default implementation computes the Euclidean Distance.
*
* @return the function for computing the distance between two instances (
* entities )
*/
default BiFunction<T, T, Double> distance() {
return (a, b) -> {
double[] aVector = this.converter().apply(a);
double[] bVector = this.converter().apply(b);
return new ChebyshevDistance().compute(aVector, bVector);
};
}
List<Feature<T, ?>> features();
BiFunction<T, T, T> add();
BiFunction<T, T, T> subtract();
BiFunction<T, Integer, T> multiply();
BiFunction<T, Integer, T> divide();
Comparator<T> comparator();
Function<T, double[]> converter();
}
Now that we have introduced the Descriptor class , we are ready to proceed with implementation of the KNNClassifier. One more thing the KNN classifier needs to know , is the function that gives the class ( label /category in the machine learning vocabulary ) of the training sample.
This function of couse is going to be passed into the KNNClassifier. To summarize the KKNClassifier needs a data descriptor, the label function, the number of neighbors and of course the training data.
One last question ( and a crucial one ) is how do I pick the number of neighbors ? And how do I know that the number of k is the optimal one ? The answer is simple. I choose the value that minimizes the error. And of course this is all about in the machine learning. I’m always seeking ways to minimize the error. So pick value K randomly ( or maybe not so randomly, a very common rule of thumb is to choose a value equal to the square root of the number of the training samples ), run the knn classifier, compute the sum of squared error (SSE). Repeat.Pick the value that resulted in the minimum SSE. You can find more info in [2].
Enough have been said, let’s see some code.
the Classifier interface
package com.tns.ml.classification;
public interface Classifier<T, C> {
C classify(T datum);
}
and the implementation
package com.tns.ml.classification;
import java.util.Collection;
import java.util.Comparator;
import java.util.Map;
import java.util.function.Function;
import java.util.stream.Collectors;
import com.tns.ml.api.Descriptor;
public class KNNClassifier<T, C> implements Classifier<T, C> {
/**
* The training data
*/
private Collection<T> data;
/**
* The number of neighbors
*/
private int k;
/**
* Function for getting the class feature value from the T entity.
*/
private Function<T, C> cFunction;
/**
* Descriptor of T
*/
private Descriptor<T> descriptor;
public KNNClassifier(int k, Collection<T> data, Function<T, C> cFunction, Descriptor<T> descriptor) {
super();
this.data = data;
this.k = k;
this.cFunction = cFunction;
this.descriptor = descriptor;
}
@Override
public C classify(T datum) {
// find nearest the k neighbors
Collection<T> neighbors = this.data.stream().sorted(Comparator.comparing(t -> distance(datum, t))).limit(k).collect(Collectors.toSet());
// let the neigbors vote
Map<C, Long> map = neighbors.stream().collect(Collectors.groupingBy(cFunction, Collectors.counting()));
// pick the most voted category
return map.entrySet().stream().sorted(Map.Entry.<C, Long> comparingByValue().reversed()).limit(1).findFirst().get().getKey();
}
private double distance(T fom, T to) {
return this.descriptor.distance().apply(fom, to);
}
}
From the code above we can see that the algorithm consists of only 3 lines of code.
Does it work ? Let’s find out.
For our testing purposes we are going to use the famous Iris Data Set which you can find at https://archive.ics.uci.edu/ml/datasets/iris.
As you have already understood we are going to create a class ( let’s say that it’s a class in our domain model ) named Iris.
package com.tns.ml.test.iris;
import java.util.Optional;
public class Iris {
private Double petalLength;
private Double petalWidth;
private Double sepalLength;
private Double sepalWidth;
private Optional<String> category;
public Iris() {
super();
}
public Iris(Double petalLength, Double petalWidth, Double sepalLength, Double sepalWidth, String category) {
super();
this.petalLength = petalLength;
this.petalWidth = petalWidth;
this.sepalLength = sepalLength;
this.sepalWidth = sepalWidth;
this.category = Optional.ofNullable(category);
}
public Double getPetalLength() {
return petalLength;
}
public void setPetalLength(Double petalLength) {
this.petalLength = petalLength;
}
public Double getPetalWidth() {
return petalWidth;
}
public void setPetalWidth(Double petalWidth) {
this.petalWidth = petalWidth;
}
public Double getSepalLength() {
return sepalLength;
}
public void setSepalLength(Double sepalLength) {
this.sepalLength = sepalLength;
}
public Double getSepalWidth() {
return sepalWidth;
}
public void setSepalWidth(Double sepalWidth) {
this.sepalWidth = sepalWidth;
}
public String getCategory() {
return this.category.get();
}
public void setCategory(String category) {
this.category = Optional.ofNullable(category);
}
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("[");
builder.append(petalLength);
builder.append(",");
builder.append(petalWidth);
builder.append(",");
builder.append(sepalLength);
builder.append(",");
builder.append(sepalWidth);
builder.append(",");
builder.append(category.orElse(""));
builder.append("]");
return builder.toString();
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((category == null) ? 0 : category.hashCode());
result = prime * result + ((petalLength == null) ? 0 : petalLength.hashCode());
result = prime * result + ((petalWidth == null) ? 0 : petalWidth.hashCode());
result = prime * result + ((sepalLength == null) ? 0 : sepalLength.hashCode());
result = prime * result + ((sepalWidth == null) ? 0 : sepalWidth.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Iris other = (Iris) obj;
if (category == null) {
if (other.category != null)
return false;
} else if (!category.equals(other.category))
return false;
if (petalLength == null) {
if (other.petalLength != null)
return false;
} else if (!petalLength.equals(other.petalLength))
return false;
if (petalWidth == null) {
if (other.petalWidth != null)
return false;
} else if (!petalWidth.equals(other.petalWidth))
return false;
if (sepalLength == null) {
if (other.sepalLength != null)
return false;
} else if (!sepalLength.equals(other.sepalLength))
return false;
if (sepalWidth == null) {
if (other.sepalWidth != null)
return false;
} else if (!sepalWidth.equals(other.sepalWidth))
return false;
return true;
}
}
As we have written above, one thing that we need to describe is the way the domain object is being converter to an array ( or vector ). For this purpose we have created a generic interface :
package com.tns.ml.converters;
public interface ArrayConverter<T> {
double[] to(T t);
T from(double[] array);
}
and the Iris specific implementation is
package com.tns.ml.test.iris;
import com.tns.ml.converters.ArrayConverter;
public class IrisArrayConverter implements ArrayConverter<Iris> {
enum Attributes {
sepal_length,
sepal_width,
petal_length,
petal_width;
}
@Override
public double[] to(Iris t) {
double[] result = new double[4];
result[Attributes.sepal_length.ordinal()] = t.getSepalLength();
result[Attributes.sepal_width.ordinal()] = t.getSepalWidth();
result[Attributes.petal_length.ordinal()] = t.getPetalLength();
result[Attributes.petal_width.ordinal()] = t.getPetalWidth();
return result;
}
@Override
public Iris from(double[] array) {
Iris iris = new Iris();
iris.setSepalLength(array[Attributes.sepal_length.ordinal()]);
iris.setSepalWidth(array[Attributes.sepal_width.ordinal()]);
iris.setPetalLength(array[Attributes.petal_length.ordinal()]);
iris.setPetalWidth(array[Attributes.petal_width.ordinal()]);
iris.setCategory(null);
return iris;
}
}
And now we need to “describe” the machine learning aspects i.e. what are the features, the functions for getting the feature values, the distance between 2 Iris objects and how an Iris object is being converter into an array or vector.
This is of course our Descriptor implementation and it’s given bellow
package com.tns.ml.test.iris;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.function.BiFunction;
import java.util.function.Function;
import org.apache.commons.math3.linear.ArrayRealVector;
import com.tns.ml.api.Descriptor;
import com.tns.ml.common.Feature;
import com.tns.ml.common.Predictor;
import com.tns.ml.converters.ArrayConverter;
public class IrisDescriptor implements Descriptor<Iris> {
protected List<Feature<Iris, ?>> features;
private ArrayConverter<Iris> arrayConverter;
public IrisDescriptor() {
this.arrayConverter = new IrisArrayConverter();
this.features = new ArrayList<>();
this.features.add(new Predictor<>(Iris::getPetalLength, 0L, "petalLength", Double.class));
this.features.add(new Predictor<>(Iris::getPetalWidth, 1L, "petalWidth", Double.class));
this.features.add(new Predictor<>(Iris::getSepalLength, 2L, "sepalLength", Double.class));
this.features.add(new Predictor<>(Iris::getSepalWidth, 3L, "sepalWidth", Double.class));
}
@Override
public List<Feature<Iris, ?>> features() {
return this.features;
}
@Override
public BiFunction<Iris, Iris, Iris> add() {
return (a, b) -> {
ArrayRealVector av = new ArrayRealVector(this.arrayConverter.to(a));
ArrayRealVector ab = new ArrayRealVector(this.arrayConverter.to(b));
return this.arrayConverter.from(av.add(ab).getDataRef());
};
}
@Override
public BiFunction<Iris, Iris, Iris> subtract() {
return (a, b) -> {
ArrayRealVector av = new ArrayRealVector(this.arrayConverter.to(a));
ArrayRealVector ab = new ArrayRealVector(this.arrayConverter.to(b));
return this.arrayConverter.from(av.subtract(ab).getDataRef());
};
}
@Override
public BiFunction<Iris, Integer, Iris> multiply() {
return (a, b) -> {
ArrayRealVector av = new ArrayRealVector(this.arrayConverter.to(a));
return this.arrayConverter.from(av.mapMultiply(b).toArray());
};
}
@Override
public BiFunction<Iris, Integer, Iris> divide() {
return (a, b) -> {
ArrayRealVector av = new ArrayRealVector(this.arrayConverter.to(a));
return this.arrayConverter.from(av.mapDivide(b).toArray());
};
}
@Override
public Comparator<Iris> comparator() {
return (a, b) -> {
ArrayRealVector av = new ArrayRealVector(this.arrayConverter.to(a));
ArrayRealVector bv = new ArrayRealVector(this.arrayConverter.to(b));
return Double.valueOf(av.getNorm()).compareTo(bv.getNorm());
};
}
@Override
public Function<Iris, double[]> converter() {
return (i) -> this.arrayConverter.to(i);
}
}
And the test case
package com.tns.ml.test.iris;
import java.io.File;
import java.util.Set;
import java.util.stream.Collectors;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.tns.ml.classification.KNNClassifier;
public class IrisClassificationTestCase {
private static final Logger LOGGER = LoggerFactory.getLogger(IrisClassificationTestCase.class);
private Set<Iris> trainingDataSet;
private Set<Iris> validationDataSet;
@Before
public void init() {
IrisCsvDataSource ds = new IrisCsvDataSource("iris" + File.separator + "iris.data");
Set<Iris> set = ds.read();
// Split 70-30
this.trainingDataSet = set.stream().limit((int) (set.size() * 0.7)).collect(Collectors.toSet());
this.validationDataSet = set.stream().filter(i -> !trainingDataSet.contains(i)).collect(Collectors.toSet());
}
@Test
public void testKnn() {
KNNClassifier<Iris, String> knn = new KNNClassifier<>(3, trainingDataSet, Iris::getCategory, new IrisDescriptor());
long correct = this.validationDataSet.stream().map(i -> {
String label = knn.classify(i);
if (i.getCategory().equals(label)) {
return 1;
}
return 0;
}).count();
double efficiency = correct / this.validationDataSet.size();
LOGGER.info(String.valueOf(efficiency));
Assert.assertEquals(true, efficiency > 0.95);
}
}
We have requested 95% of the samples to be true. And guess what: it works.
We have implemented a 3-line KNN. Does it worth ? Is it better ? Would you prefer to write R scripts, convert domain objects to R data frames and vice versa, add system libraries in order to execute sql queries from R scripts and maybe add a network burden to your application ( Java-Rserver ).
It seems to me that the second road is more time consuming.
A very strong argument argument might me the visualization capabilities. That’s true. Until a future post that we are going to unlock the power of the combination D3/Angular2/4.
Another argument might be that we have chosen a relatively easy algorithm. True. Until a future post that we are going to show how easy you can implement more complicated things ( e.g. PCA for dimensionality reduction ).
But for the time being I think that the phrase “Don’t re-invert the wheel” its not always true.
What do you think ?
You can find the source here : https://github.com/sergouniotis/ml
[1]Gareth James-Daniela Witten-Trevoer Hastie-Robert Tibshirani, 2017, An Introduction to Statistical Learning
[2]Iris Data Set, 1936, https://archive.ics.uci.edu/ml/datasets/iris